

CF631D.Messenger
普及/提高-
通过率:0%


AC君温馨提醒
该题目为【codeforces】题库的题目,您提交的代码将被提交至codeforces进行远程评测,并由ACGO抓取测评结果后进行展示。由于远程测评的测评机由其他平台提供,我们无法保证该服务的稳定性,若提交后无反应,请等待一段时间后再进行重试。
题目描述
Each employee of the "Blake Techologies" company uses a special messaging app "Blake Messenger". All the stuff likes this app and uses it constantly. However, some important futures are missing. For example, many users want to be able to search through the message history. It was already announced that the new feature will appear in the nearest update, when developers faced some troubles that only you may help them to solve.
All the messages are represented as a strings consisting of only lowercase English letters. In order to reduce the network load strings are represented in the special compressed form. Compression algorithm works as follows: string is represented as a concatenation of n blocks, each block containing only equal characters. One block may be described as a pair (li,ci) , where li is the length of the i -th block and ci is the corresponding letter. Thus, the string s may be written as the sequence of pairs 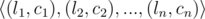 .
.
Your task is to write the program, that given two compressed string t and s finds all occurrences of s in t . Developers know that there may be many such occurrences, so they only ask you to find the number of them. Note that p is the starting position of some occurrence of s in t if and only if tptp+1...tp+∣s∣−1=s , where ti is the i -th character of string t .
Note that the way to represent the string in compressed form may not be unique. For example string "aaaa" may be given as 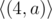 ,
, 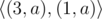 ,
, 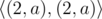 ...
...
布雷克技术 "公司的每位员工都使用一个特殊的信息应用程序 "布雷克信使"。所有员工都喜欢并经常使用这款应用程序。但是,还缺少一些重要的功能。例如,许多用户希望能够搜索消息历史记录。开发人员已经宣布,新功能将在最近的更新中出现,但开发人员面临着一些麻烦,只有您能帮助他们解决。
所有信息都以字符串的形式表示,其中只有小写英文字母。为了减少网络负荷,字符串以特殊的压缩形式表示。压缩算法的工作原理如下:字符串表示为 n 块的连接,每个块只包含相等的字符。一个块可以描述为一对 (li, ci) ,其中 li 是第 i 个块的长度, ci 是相应的字母。因此,字符串 s 可以写成一对序列 .。
您的任务是编写一个程序,在给定两个压缩字符串 t 和 s 的情况下,找到 t 中所有出现 s 的位置。开发人员知道可能会有很多这样的情况,因此他们只要求您找到个数。请注意, p 是 t 中出现的 s 的起始位置,当且仅当 tptp+1...tp+∣s∣−1=s ,其中 ti 是字符串 t 的第 i 个字符。
请注意,以压缩形式表示字符串的方法可能不是唯一的。例如,字符串"aaaa" 可表示为 , , , ...
输入格式
The first line of the input contains two integers n and m ( 1<=n,m<=200000 ) — the number of blocks in the strings t and s , respectively.
The second line contains the descriptions of n parts of string t in the format " li - ci " ( 1<=li<=1000000 ) — the length of the i -th part and the corresponding lowercase English letter.
The second line contains the descriptions of m parts of string s in the format " li - ci " ( 1<=li<=1000000 ) — the length of the i -th part and the corresponding lowercase English letter.
输入
输入的第一行包含两个整数 n 和 m ( 1 ≤ n, m ≤ 200 000 ) --分别是字符串 t 和 s 中的块数。
第二行包含字符串 t 中 n 个部分的描述,格式为" li - ci " ( 1 ≤ li ≤ 1 000 000 ) --第 i 个部分的长度和对应的小写英文字母。
第二行包含字符串 s 中 m 部分的描述,格式为" li - ci " ( 1 ≤ li ≤ 1 000 000 ) - 第 i 部分的长度和相应的小写英文字母。
输出格式
Print a single integer — the number of occurrences of s in t .
输出
打印一个整数 - t 中 s 出现的次数。
输入输出样例
输入#1
5 3 3-a 2-b 4-c 3-a 2-c 2-a 2-b 1-c
输出#1
1
输入#2
6 1 3-a 6-b 7-a 4-c 8-e 2-a 3-a
输出#2
6
输入#3
5 5 1-h 1-e 1-l 1-l 1-o 1-w 1-o 1-r 1-l 1-d
输出#3
0
说明/提示
In the first sample, t = "aaabbccccaaacc", and string s = "aabbc". The only occurrence of string s in string t starts at position p=2 .
In the second sample, t = "aaabbbbbbaaaaaaacccceeeeeeeeaa", and s = "aaa". The occurrences of s in t start at positions p=1 , p=10 , p=11 , p=12 , p=13 and p=14 .
注意
在第一个示例中, t = "aaabbccaaacc" ,字符串 s = "aabbc" 。字符串 s 在字符串 t 中唯一出现的位置是 p = 2 。
在第二个示例中, t = "aaabbbbbbaaaaacccceeeeeeaa", s = "aaa". t 中 s 的出现从位置 p = 1 、 p = 10 、 p = 11 、 p = 12 、 p = 13 和 p = 14 开始。
输入解题思路,AI测评打分。不知道怎么写?